Track Introduction
当前,人工智能与决策科学迈入以智能体为核心的新阶段,腾讯开悟平台聚焦智能体决策算法,是多智能体强化学习与复杂决策研究前沿,推动 AI 从封闭棋盘博弈走向开放复杂环境模拟,搭建起理论研究与产业级决策应用的桥梁。本赛道以《王者荣耀》复杂对抗环境为场景,考察智能体在信息不完整、实时对抗等场景的决策能力,全面检验算法、策略及多智能体协同等能力,贴合产业落地需求。赛道聚焦强化学习等核心技术,契合决策智能发展与产业需求,是实现感知智能向认知决策跃迁的关键,将深刻影响未来智能系统的发展。
Target Participants
全国高等学校(本科类和高职高专类院校)具有正式学籍的全日制在校学 生(含 2026 年应届毕业生,本专科、研究生不限)可以组队参赛。
● 上述高校毕业不超过 5 年(2021 年后毕业)的毕业生可组队参赛。
● 参赛队员允许跨校组队。
● 每参赛团队仅限选一竞赛类别参赛,每位队员限参加一支团队,禁止不同参赛团队之间共用队员。
● 每参赛团队队员上限为5人,指导老师上限为2人。
● 参赛选手的专业范围和所属学院不限。建议参赛团队选择能力互补、专业背景多样化的选手组队。
Schedule
About the Challenge:In this challenge, participating teams need to use algorithms to train models that drive agents to learn movement strategies through continuous exploration of the map. They must wisely use summoner skills and acceleration boosts to reach the endpoint within a limited time while collecting as many treasure chests as possible.
The map features starting and ending points, roads, obstacles, acceleration boosts, and treasure chests. Agents have a limited local field of view and can move around the map, deploy summoner skills, and acquire rewards contained within the treasure chests. (A comprehensive development guide with more details will be provided on the platform following successful registration.)
Objective:Participating teams must locally train and submit a model within a limited time. Their goal is to control agents on the assessment map to gather as many points as possible in the least amount of time, fulfilling the mission of embarking on a return adventure to the mystic realm.

Ranking Rules: After the submission phase ends, the system will automatically execute the challenge with the latest model submitted by each participating team. Teams will be ranked according to their scores, and these rankings will constitute the final results for this phase of the competition.
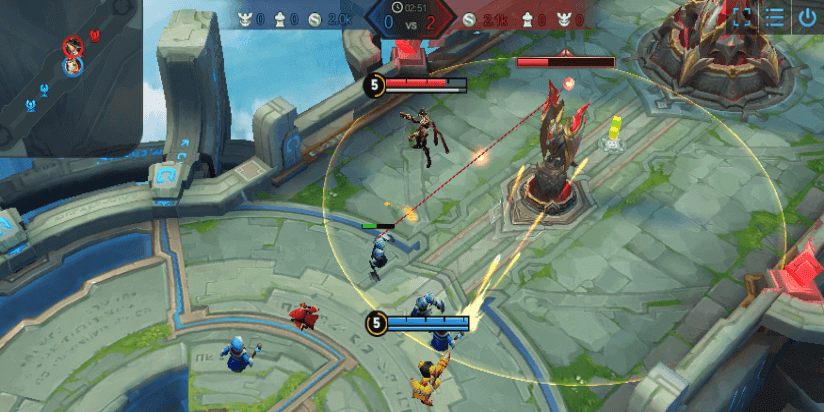
About the Challenge:IIn this challenge, participating teams are required to train model-driven agents using algorithms. These agents will continuously explore the 1v1 map of the game "Honor of Kings" to learn the optimal strategy, aiming to be the first to destroy the opponent's camp crystal to achieve victory.
The map used in this challenge is elongated, with resurrection points for both teams' agents at each end, and a crystal belonging to each camp positioned in front of the resurrection points. These crystals continuously produce minions for their respective camps, which automatically advance towards the opponent's camp, attacking defense towers, crystals, and heroes along the way. Ahead of the crystals are the camp's defense towers, capable of attacking enemy heroes and minions within range. Agents have the freedom to move around the map and unleash skills at will. (Detailed instructions will be provided in the development guide available on the platform after successful registration)
Objective:Teams are required to utilize the allocated computing resources within a specified time to train their models. The objective is to let these models to learn the optimal winning strategy through continuous exploration of the 1v1 maps, enabling them to secure as many victories as possible in matches against other teams.
Ranking Rules:
After the submission phase ends, the system will automatically conduct multiple rounds of matchmaking using the latest model submitted by participating teams. Each team will compete in an equal number of matches against all opponents in their division and will be ranked based on their accumulated points.
In each round of matchmaking between two teams, all heroes from both sides must participate, with each hero facing off against every opposing hero across two rounds. Winning a round earns 1 point, while a loss yields no points.
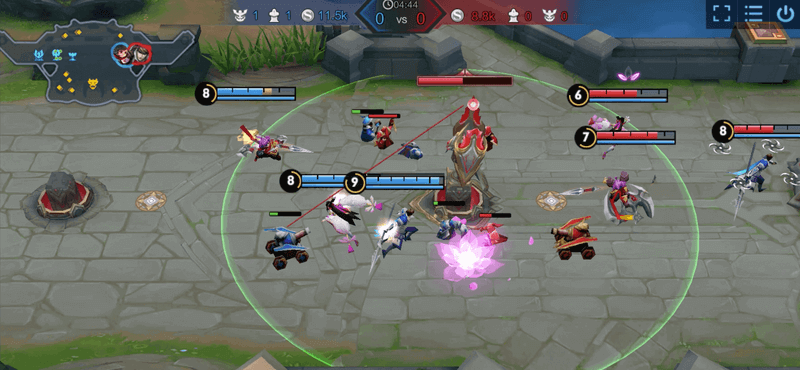
About the Challenge:In this challenge, teams train models to control 2 agents working alongside 1 platform-bot teammate. Their goal is to master the best strategy on the Honor of Kings 3v3 map, aiming to destroy the opponent's base crystal first to win.
The map features a main lane flanked by upper and lower jungle areas. Each team's spawn points are at the map's ends, with their base crystals spawning minions that advance towards the enemy, attacking towers, crystals, and heroes en route. Defense towers protect the crystal, targeting enemy heroes and minions within their range. The jungle areas are key for gaining gold and experience, shared between both teams but with camp-specific entry restrictions. (Hint: Use these to escape enemies.)
Agents can freely move and use skills on the map. Over time, they earn gold and experience, with significant rewards for killing jungle monsters, enemy minions, heroes, or towers. The team that destroys the enemy crystal claims victory.
Objective:Participating teams must train their models within a limited time using allocated computational resources. They are to work with platform-bot teammates to constantly explore the 3v3 maps, aiming to discover the most effective strategies for collaborative victory. The objective is to secure the highest number of wins in matches against other teams.
Ranking Rules: After the submission phase ends, the system will automatically run multiple rounds of battles using the most recently submitted models from the participating teams. In this phase, teams will face off in an equal number of rounds against all other teams, with rankings based on the points each team accumulates.
In each match-up between two teams, all heroes must be deployed and matched against each opposing team's heroes in turn, leading to two matches with teams swapping sides. A win awards 1 point, while a loss awards no points.
Recommendations
It is advised that each team possess at least one computer adhering to the recommended specifications below to establish the local environment for development and training.