Track Introduction
This track is jointly customized by Tencent AI Arena Platform and Hangzhou Yushu Technology Co., Ltd. Teams are required to train their own quadruped robot motion control models to complete tasks in virtual complex environments. The focus is on developing single-agent reinforcement learning algorithms, designing reward functions, and embodied intelligent motion control.
Target Participants
This track is open to full-time students from global higher education institutions, including associate degree, undergraduate, and postgraduate (master's/PhD) students. Participants must form teams of 2 to 5 students from the same institution, with no restrictions on their major. Each participant may only join one team. Additionally, each team must be guided by 1 to 3 faculty members from the same institution.
Please choose the appropriate equipment option based on your team's situation. Teams with the required equipment should select the [With Equipment] label. Equipment Requirement: Only the [Unitree Go2 edu Standard Edition] is permitted for use in this competition. Teams without the specified equipment should select the [No Equipment] label.
Rewards
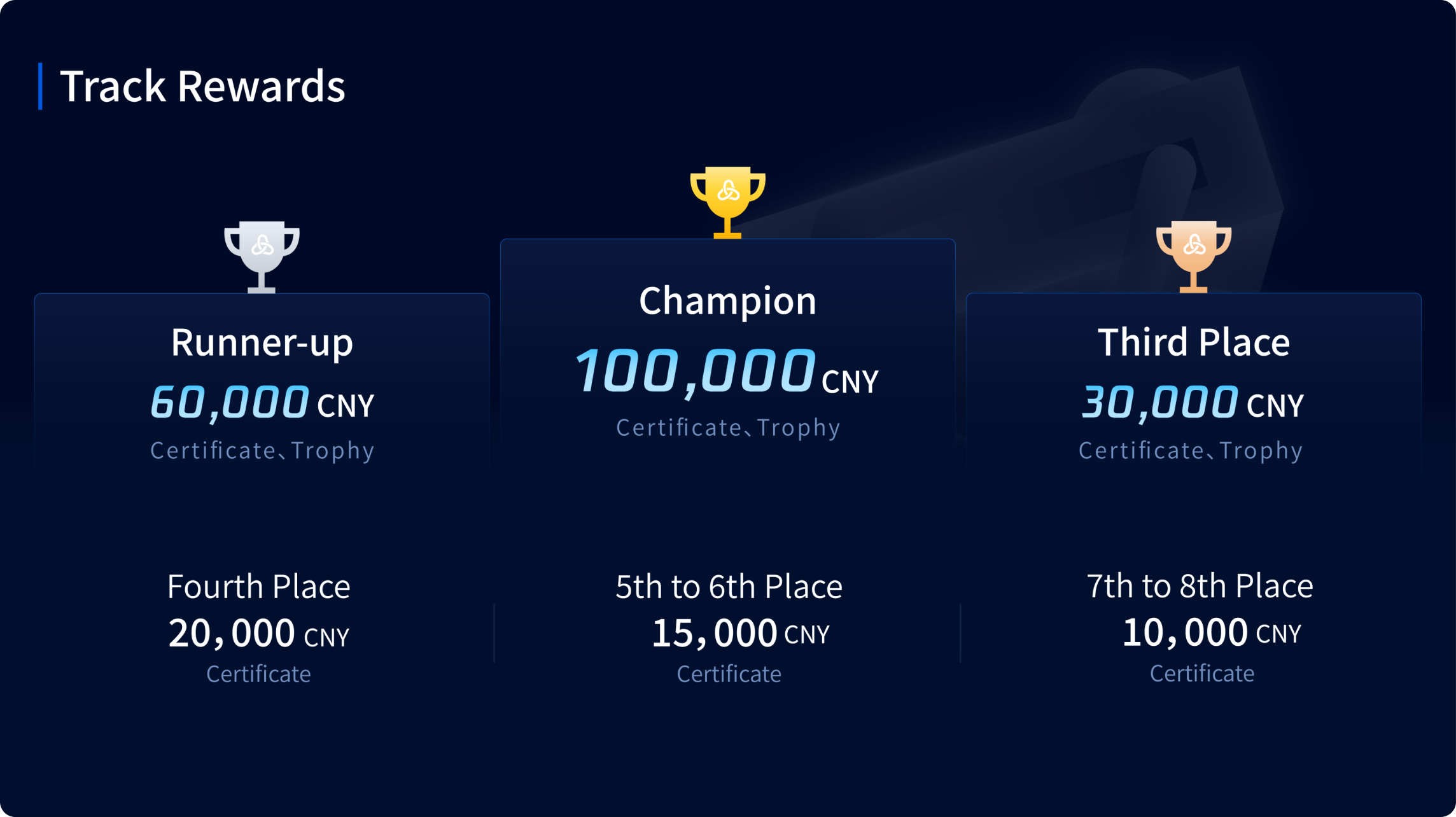
The prize money for this track is set as above, with amounts in Chinese Yuan (CNY) and pre-tax.
In addition to the prize money, participating teams will also receive the following rewards:
Teams that complete the preliminary round (by successfully submitting a model and passing verification) will receive an official certificate of participation.
Outstanding participants may be offered internship opportunities related to Tencent’s AI Arena Program. Sepcific details will be notified separately.
Schedule
About the Challenge:In this challenge, participating teams need to use algorithms to train models that drive agents to learn movement strategies through continuous exploration of the map. They must wisely use summoner skills and acceleration boosts to reach the endpoint within a set time frame while collecting as many treasure chests as possible.
The map features starting and ending points, roads, obstacles, acceleration boosts, and treasure chests. Agents have a local field of view and can move around the map, deploy summoner skills, and acquire rewards contained within the treasure chests. (A comprehensive development guide with more details will be provided on the platform following successful registration.)
Objective:Participating teams must locally train and submit a model within a given timeframe. Their goal is to control agents on the assessment map to gather as many points as possible in the least amount of time, fulfilling the mission of embarking on a return adventure to the mystic realm.

Ranking Rules: After the submission phase ends, the system will automatically execute the challenge with the latest model submitted by each participating team. Teams will be ranked according to their scores, and these rankings will constitute the final results for this phase of the competition.
Advancement Rules: The top 40 teams on the scoreboard will advance to the next stage.
About the Challenge:In this challenge, participants will train and optimize motion control algorithms using reinforcement learning on a simulation platform. The goal is to control the quadruped robot, Go2, through a complex competition scenario and reach the finish line in a virtual environment.
Objective:Teams are required to train and submit a model within a specified time and control the quadruped robot to complete the course in the shortest time possible. Teams will repeatedly run the trained model and record the number of successful times the quadruped robot reaches the finish line. The robot's motion control ability will be assessed based on success rate, fastest completion time, stability, and other indicators, with rankings determined after a comprehensive evaluation.

Scoring Rules:After submitting their model, participating teams will be scored based on the following indicators:
Number of successful finishes
Fastest completion time
Stability
Advancement Rules:
The top 16 teams on the scoreboard will advance to the final, and each will receive a loan of the competition equipment (Unitree Go2 edu Standard Edition).
About the Challenge:In this challenge, teams must train the motion control algorithm for the quadruped robot using reinforcement learning. The objective is to remotely control the Go2 robot through a complex racecourse and reach the finish line.
Objective:Teams need to train and deploy a model within the given time on the designated quadruped robot Go2, using only their own trained motion control algorithms. The use of AI motion modes or advanced modes from the Yushu open SDK, and related AI motion service interfaces, is prohibited. Teams must also run the detection plugin provided by the event organizers in real-time.

Ranking Rules: The time taken by each team’s equipment to travel from the starting point to the finish line will be calculated. The team with the shortest time will be ranked the highest.